Velocity Model Building From Raw Shot Gathers Using Machine Learning
Seismic data interpretation is a cornerstone of subsurface exploration, playing an essential role in industries such as oil and gas exploration, environmental studies, and geotechnical engineering. One of the most critical tasks in seismic data interpretation is creating accurate velocity models, which describe the speed at which seismic waves travel through the Earth’s subsurface. Traditionally, this process has been labor-intensive and reliant on expert knowledge, but the advent of machine learning is transforming how velocity models are built. This article explores the process of constructing velocity models from raw shot gathers using machine learning, emphasizing the advancements and challenges in this field.
Understanding Raw Shot Gathers
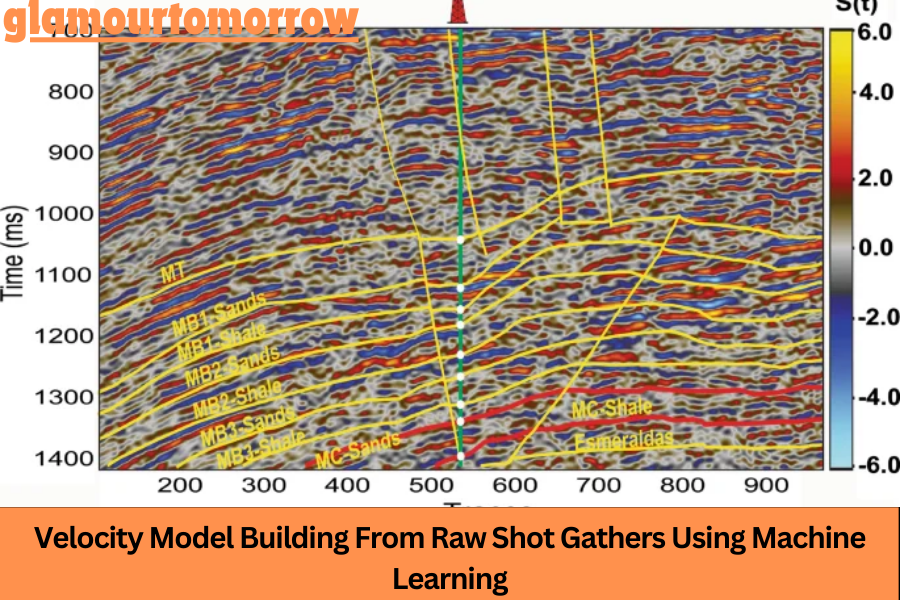
Before diving into the machine learning aspects, it’s crucial to understand what raw shot gathers are. A shot gather is a collection of seismic data recorded at multiple receivers (geophones) following a single seismic source event, commonly referred to as a “shot.” These gathers are essentially snapshots of how seismic waves propagate through the subsurface, providing valuable information about the Earth’s interior.
However, raw shot gathers are often complex and noisy, requiring significant preprocessing before they can be used to create velocity models. In the past, this preprocessing was a manual task, requiring the expertise of geophysicists to filter out noise and interpret the data. Today, machine learning models are increasingly being used to automate this process, making it more efficient and less prone to human error.
Importance of Velocity Models
Velocity models are foundational to seismic data interpretation. These models describe how seismic waves travel through the Earth’s subsurface, enabling geophysicists to map different geological layers, identify rock types, and locate natural resources like oil and gas. Accurate velocity models are also crucial for assessing earthquake risks and making informed decisions in drilling operations.
Errors in velocity models can lead to significant consequences, such as incorrect interpretations of the subsurface, costly drilling mistakes, or missed opportunities to discover natural resources. Therefore, improving the accuracy and efficiency of velocity model building is a high priority in geophysics. This is where machine learning can make a substantial impact.
Traditional Methods of Velocity Model Building
Historically, building velocity models was a manual and iterative process. Geophysicists would analyze shot gathers, apply mathematical models, and repeatedly simulate seismic wave propagation to refine their velocity models. While this method could produce accurate results, it was time-consuming, required deep expertise, and was challenging to scale with large datasets.
One of the main limitations of traditional methods is their reliance on expert knowledge. Interpreting seismic data is inherently subjective, and different geophysicists may arrive at different conclusions when analyzing the same data. Additionally, the manual process of refining velocity models can be prone to errors, especially when dealing with noisy or incomplete data.
Challenges in Velocity Model Building
Building accurate velocity models from seismic data is fraught with challenges. First and foremost, seismic data is often noisy, requiring extensive preprocessing to remove artifacts and enhance signal quality. This noise can come from various sources, including environmental factors, equipment errors, or surface waves.
Another challenge is the inversion process used to derive velocities from seismic data. Seismic inversion is often an ill-posed problem, meaning that small changes in the input data can lead to large variations in the resulting velocity model. This sensitivity makes the inversion process computationally intensive and difficult to automate.
Moreover, the subjectivity of manual interpretation adds another layer of complexity. Different experts may interpret the same data differently, leading to inconsistencies in velocity models. The combination of data complexity, the need for extensive preprocessing, and the inherent subjectivity of interpretation underscores the need for more automated, robust methods—enter machine learning.
Introduction to Machine Learning in Seismic Data
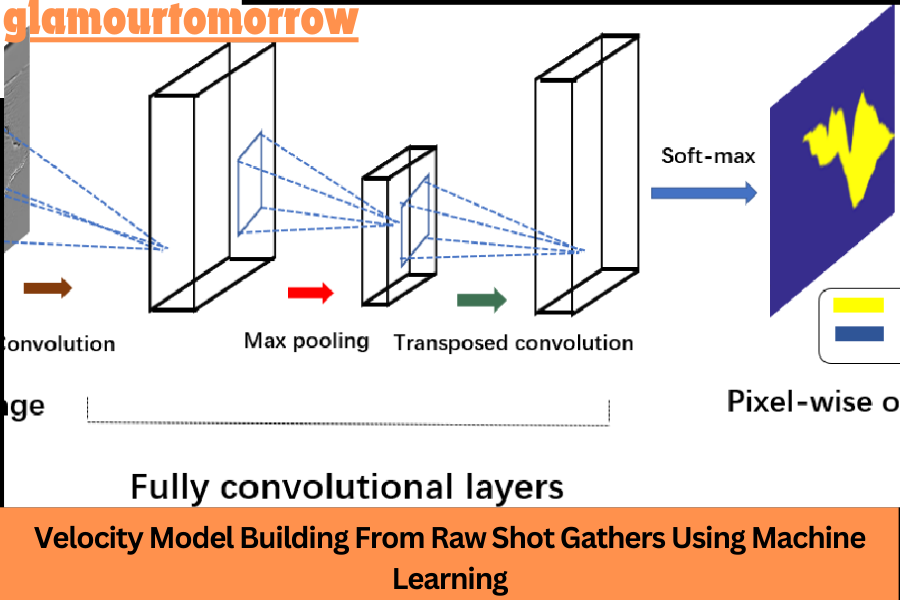
Machine learning (ML) offers a powerful solution to the challenges of velocity model building. By training algorithms on large datasets, ML models can learn to recognize patterns in seismic data that correspond to specific subsurface features. This capability allows for the automation of tasks that were traditionally handled by expert interpreters, such as identifying geological layer boundaries and estimating seismic velocities.
One of the key advantages of machine learning is its ability to process vast amounts of data quickly and efficiently. In modern seismic surveys, datasets can be enormous, containing millions of shot gathers. Machine learning models can handle this scale, enabling geophysicists to build more accurate velocity models in less time.
Types of Machine Learning Used in Seismic Data
Various machine learning techniques are applicable to seismic data processing, each with its own strengths.
- Supervised Learning: This is the most commonly used type of machine learning in seismic data processing. Supervised learning models are trained on labeled datasets, where the correct outcomes are known. In the context of velocity model building, this means training the model on shot gathers with known velocity models. Once trained, the model can predict velocity models for new, unseen shot gathers.
- Unsupervised Learning: Unlike supervised learning, unsupervised learning does not require labeled data. Instead, it identifies patterns or clusters within the data. In seismic data processing, unsupervised learning can be used to group shot gathers into different regions based on their similarities, which can then be interpreted to build velocity models.
- Reinforcement Learning: This is a more advanced machine learning technique that involves training an agent to make decisions based on feedback from the environment. While still in the experimental stage for seismic applications, reinforcement learning holds promise for tasks like optimizing the parameters of seismic inversion algorithms.
Raw Shot Gathers to Velocity Model: Process Overview
The process of building a velocity model from raw shot gathers using machine learning involves several key steps:
- Data Preprocessing: The first step is to preprocess the raw shot gather data. This involves removing noise, correcting for distortions caused by the Earth’s surface, and normalizing the data so that it can be used by machine learning algorithms.
- Feature Engineering: Once the data has been preprocessed, the next step is to extract features from the shot gathers. Features might include seismic attributes like travel time, amplitude, and frequency content, which provide valuable information about the subsurface. Feature engineering is crucial for ensuring that the machine learning model can effectively learn from the data.
- Model Training: With the features extracted, the next step is to train the machine learning model. This involves feeding the model a labeled dataset of shot gathers, where the correct velocity model is known. The model learns to associate specific patterns in the shot gathers with corresponding subsurface features.
- Model Application: Once the model has been trained, it can be applied to new, unlabeled shot gathers to predict their velocity models. These predictions can then be validated against additional data or compared to results from traditional methods to ensure accuracy.
Data Preprocessing for Machine Learning
Data preprocessing is a critical step in velocity model building from raw shot gathers. Seismic data is often noisy and may contain various distortions that can obscure the underlying signals. Effective preprocessing is essential for ensuring that the machine learning models can accurately interpret the data.
Key preprocessing steps include:
- Noise Removal: Seismic data can contain noise from various sources, such as environmental conditions, equipment errors, or surface waves. Noise removal techniques, such as filtering or wavelet denoising, are used to enhance the signal quality.
- Data Normalization: To ensure that the data is suitable for machine learning, it must be normalized. This involves scaling the data to a standard range, making it easier for the model to learn from the data.
- Dimensionality Reduction: In some cases, it may be necessary to reduce the complexity of the data while preserving important patterns. Techniques like Principal Component Analysis (PCA) can be used to achieve this, making the data more manageable for machine learning algorithms.
Feature Engineering from Shot Gathers
Feature engineering is the process of selecting and transforming raw data into meaningful inputs for a machine learning model. In seismic data processing, this might involve calculating seismic attributes such as:
- Travel Time: The time it takes for seismic waves to travel from the source to the receiver. This is a crucial feature for determining subsurface velocities.
- Amplitude: The strength of the seismic signal, which can provide information about the types of rocks and fluids in the subsurface.
- Frequency Content: The range of frequencies present in the seismic signal, which can help distinguish between different geological layers.
Feature engineering can also involve applying dimensionality reduction techniques like PCA to reduce the number of features while retaining the most important information. This step is crucial for ensuring that the machine learning models can operate efficiently, especially when dealing with large seismic datasets.
Labeling in Machine Learning for Velocity Models
Labeling is a critical aspect of supervised machine learning. In the context of velocity model building, labeling involves providing the correct velocity model for each shot gather in the training set. However, generating these labels can be challenging, as it often requires manual interpretation or the use of synthetic data.
One approach to labeling involves using forward modeling to generate synthetic shot gathers with known velocity models. These synthetic datasets can then be used to train the machine learning model. Another approach is to use partially labeled data, where only a subset of the shot gathers have known velocity models, and the machine learning model is used to infer the labels for the remaining data.
Conclusion
Machine learning is revolutionizing the process of velocity model building from raw shot gathers. By automating complex tasks and improving the accuracy of seismic interpretations, machine learning enables faster, more reliable subsurface imaging. As these technologies continue to evolve, the future of seismic data processing looks promising, with increased efficiency, accuracy, and scalability on the horizon.
Machine learning is not a replacement for traditional methods but rather a powerful complement. By reducing the manual labor involved in seismic data interpretation and increasing the accuracy of velocity models, machine learning is helping geophysicists make better decisions, faster. As the field continues to advance, we can expect even more sophisticated machine learning models that will further enhance our ability to understand the Earth’s subsurface.
Keep up-to-date with breaking news and updates on glamourtomorrow





